PaloAlto still investigating, this is the response:
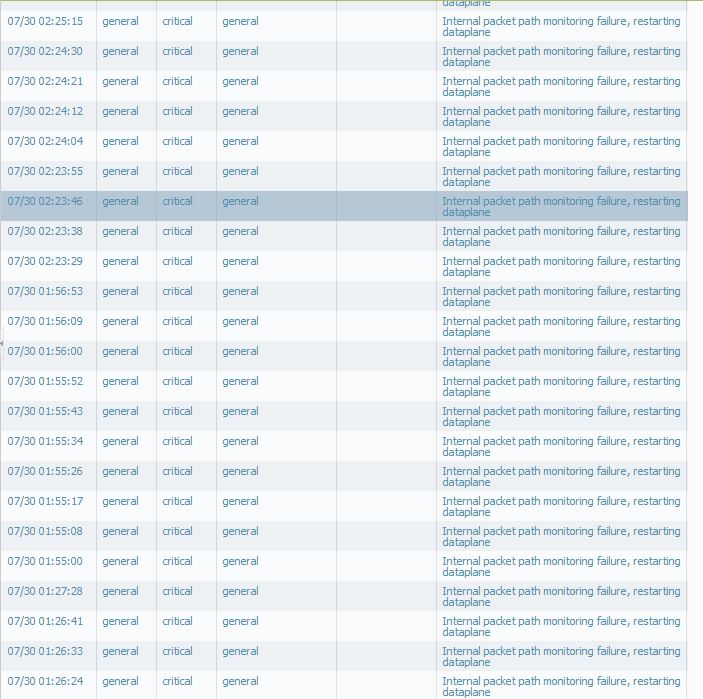
"From the analysis of the collected the dataplane restart happened initially at 17:02 on 06/15 where an internal path monitoring failure detected . The internal path monitoring failure occurs when internal monitor packets between the daemons in the firewall are not ACKed timely. When the packets are not ACKed, the firewalls assumes some daemon is down and triggers a dataplane restart.
2014/06/15 16:56:45 high ha state-c 0 HA Group 30: Moved from state Passive to state Active
2014/06/15 17:02:39 high general general 0 9: path_monitor HB failures seen, triggering HA DP down
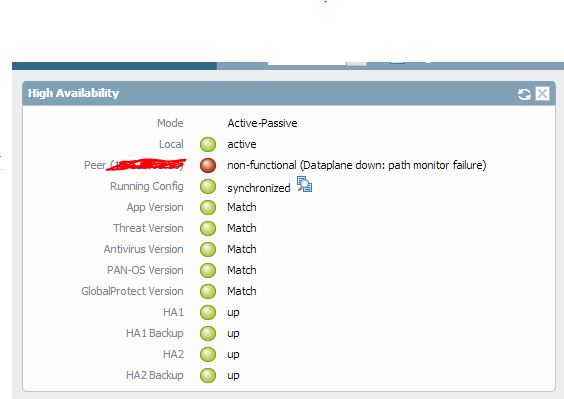
2014/06/15 17:02:39 critical ha datapla 0 HA Group 30: Dataplane is down: path monitor failure
2014/06/15 17:02:39 critical ha state-c 0 HA Group 30: Moved from state Active to state Non-Functional
2014/06/15 17:02:53 high general general 0 flow_mgmt: exiting because missed too many heartbeats
2014/06/15 17:03:17 critical general general 0 Internal packet path monitoring failure, restarting dataplane
Device became active after the restart of dataplane and again detected the internal path monitoring failure and triggered the data-plane restart . This time dataplane didn't restart and was down causing the device to be in non-functional state until you rebooted the device next day
2014/06/15 17:07:30 info ha state-c 0 HA Group 30: Moved from state Initial to state Passive
2014/06/15 17:09:42 high ha state-c 0 HA Group 30: Moved from state Passive to state Active
2014/06/15 17:33:46 high general general 0 9: path_monitor HB failures seen, triggering HA DP down
2014/06/15 17:33:46 critical ha datapla 0 HA Group 30: Dataplane is down: path monitor failure
2014/06/15 17:33:46 critical ha state-c 0 HA Group 30: Moved from state Active to state Non-Functional
2014/06/15 17:34:25 critical general general 0 Internal packet path monitoring failure, restarting dataplane
014/06/15 22:24:45 high general general 0 flow_mgmt: exiting because missed too many heartbeats
2014/06/15 22:25:05 critical general general 0 Internal packet path monitoring failure, restarting dataplane
The DP1 CPU was under high load for that moment right before the dataplane restart and did see some software buffer depletion which could have triggered the internal path failure. "
They opened a bug with development team to validate the findings and analyze the crash files and logs further. And they want us to call them if this happens again, so they can do a live debug.