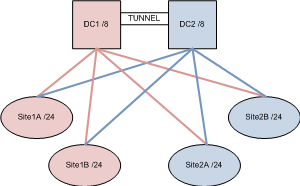
Start with creating a drawing and publish it here with ip-ranges attached (you can use faked ip's but so we have something to discuss around).
As I see it you have 3 types of "sites":
* Client-site (x number of them)
* West-site (DC1)
* East-site (DC2)
Each client-site have two IPSEC tunnels, one to DC1 and one to DC2.
The range at client-site is CLIENT/24 (or whatever size you use), range at west-site is DC1/16 and east-site DC2/16 (the size is just an example).
The client-site then have the following routing:
DC1/16 nexthop tunnel1
DC2/16 nexthop tunnel2
0.0.0.0/0 nexthop tunnel1
0.0.0.0/0 nexthop tunnel2
(im not sure if PA supports ECMP (Equal Cost Multipath), if not you can use different metrics so client-sites located to the west use DC1 as primary and DC2 as secondary while client-sites located to the east use DC2 as primary and DC1 as secondary).
Now at DC1 you have the following routing setup (tunnel999 is the site-to-site (DC1-DC2) tunnel):
CLIENT1/24 nexthop tunnel1 metric 1
CLIENT1/24 nexthop tunnel999 metric 2
CLIENT2/24 nexthop tunnel2 metric 1
CLIENT2/24 nexthop tunnel999 metric 2
...
DC2/16 nexthop tunnel999
0.0.0.0/0 nexthop INTERNETFW_DC1
and the opposite at DC2:
CLIENT1/24 nexthop tunnel1 metric 1
CLIENT1/24 nexthop tunnel999 metric 2
CLIENT2/24 nexthop tunnel2 metric 1
CLIENT2/24 nexthop tunnel999 metric 2
...
DC1/16 nexthop tunnel999
0.0.0.0/0 nexthop INTERNETFW_DC2
Downside here is that defgw towards Internet is only available locally. In order for this to work it would be great if you can setup your Bluecoat webproxy as a non-transparent proxy. Meaning that anything that needs/wants to reach Internet must use the inside-ip of your Bluecoat as "forward-proxy".
If you have a loadbalancer such as F5 or similar you can setup a virtual ip-range which is the ip that the client/servers use as forward-proxy and then the loadbalancer at each site will forward the traffic to the Bluecoat which is currently the best option.
The point here is that in your core you will only have RFC1918 addresses and could setup an IDS to set off an alarm in case a non-RFC1918 ip address shows up (or if you have your PA as core let the PA sound this alarm).
If you do so then you wont need these routes at each client-site:
0.0.0.0/0 nexthop tunnel1
0.0.0.0/0 nexthop tunnel2
This way stuff at DC1 should be able to reach DC2 and the other way around along with clients reaching both DC's.
The above can be optimized by using a dynamic routing between DC1 and DC2 in order to avoid routing loops (if CLIENT2/24 disconnects the packets for CLIENT2/24 would with static routing need to burst between the sites until the TTL hits 0) but on the other hand you would then need to rely on that the dynamic routing protocol is always functional. Another risk with dynamic routing is that you could accidently pass all traffic through a poor client-site in case the DC1-DC2 connection breaks.